本文共 4122 字,大约阅读时间需要 13 分钟。
上一篇文章内容为车牌定位,这篇文章从原理及代码角度分析如何分割字符。
文章目录
一. 分割字符的目的
定位车牌仅仅是为了找出其车牌的左上角及右下角的坐标。框出车牌终究只是给我们了一个视觉效果。找出车牌位置的目的就是为了分割字符,为什么要分割字符呢。这要从我们的机器学习说起了,总体的车牌识别大概是个什么流程呢。
- 首先通过某种算法定位车牌。
- 其次从车牌位置按序取出字符。
- 识别字符。
机器学习就是在最后一步发挥大作用的,或许我们可以通过一系列参数的调整,或者某些算法的调整,识别一些简单的英文,数字。但是识别必然会非常有限。那么如先所说,这一张图片在计算机眼中代表的是一个一维或者多维的矩阵。车牌上的各种字符数字有其自己的规划,那我们如果将图片转化为二值图片,并且将字符凸显出来,那么构造某种机器学习算法对某个字符的数据集做训练,并得到一个模型,这个模型理所当然的具有判断某种尺寸的照片上含有什么字符的功能。而作为前提,分割字符也是必要做好的。
二. 分割字符原理:

像这样一幅车尾图,在经过第一轮找到车牌位置之后,图片大致的会像这样。
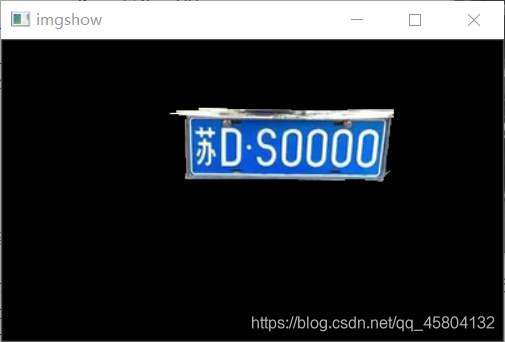
如果将其变化二值图片的话,就是,这样。
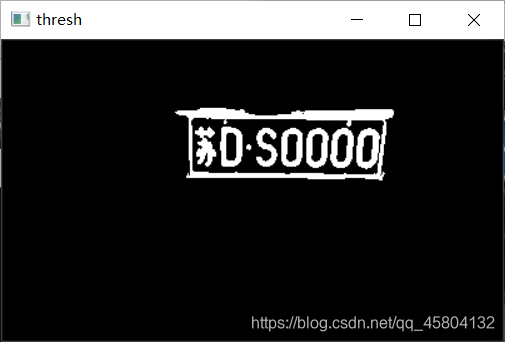
对字符的分割采用以列计数像素点的思路。如"苏"与"D"之间,明显是存在这样一道黑色的缝的,后面的字符同样具备这样的特征,那么依此为参考,可以对图片从左至右滑,做遍历。一直统计白色像素点和黑色像素点的个数,并设置阈值,比如,如果黑色位置开始往右走五,还没有到达白色的阈值,那么我们就认为该黑色部分为边界。只有一个特殊情况需要考虑,那就是数字存在"1"的情况下,会很窄,因此我们直接大胆估计它就是一。(这里也不需要再将1裁剪下来,只需要在样本库中copy一个1就可以了。)裁剪图片的话,还是一个找轮廓加判断的过程,与当时这一步如出一辙。
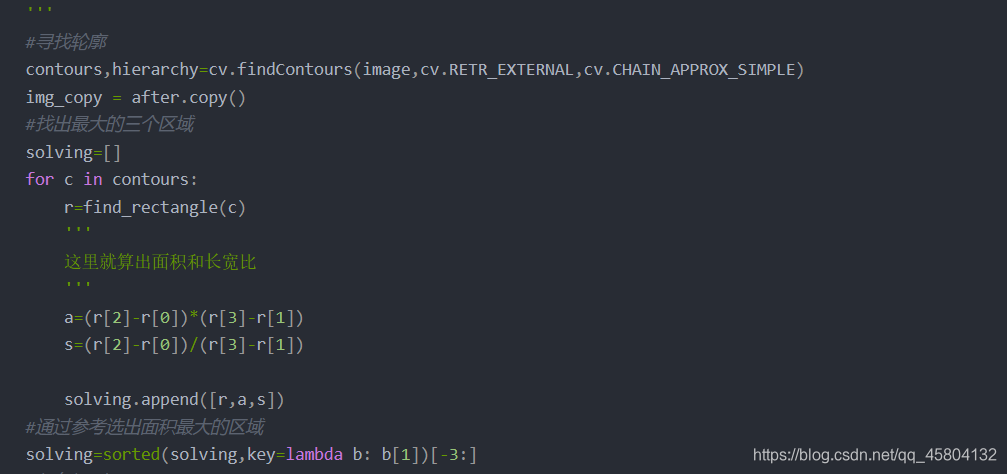
三. 代码
#分割车牌 def cut_license(image,rect): #获取高度和宽度 注意切割的参数为x,y,w,h rect[2]=rect[2]-rect[0] rect[3]=rect[3]-rect[1] #传入参数要求为元组 rect=tuple(rect) #掩膜 mask=np.zeros(image.shape[:2],np.uint8) ''' bdgModel,fgdModel-算法内部使用的数组.你只需要创建两个大小为(1,65),数据类型为np.float64的数组。 ''' #创建背景模型 大小只能为13*5,行数只能为1,单通道浮点型 bgdModel=np.zeros((1,65),np.float64) #创建前景模型 fgdModel=np.zeros((1,65),np.float64) #分割图像 cv.grabCut(image,mask,rect,bgdModel,fgdModel,5,cv.GC_INIT_WITH_RECT) mask2=np.where((mask==2)|(mask==0),0,1).astype('uint8') mask2=mask2[:,:,np.newaxis] img_show=image*mask2 return img_show'''对车牌图像的二值化'''def plate_binary(plate): ''' 车牌图片二值化 ''' #转化为灰度图 gray=cv.cvtColor(plate,cv.COLOR_BGR2GRAY) #去除噪音 gray=cv.filter2D(gray,-1,np.ones((3,3),np.float32)/9) #图像二值化 ret,thresh=cv.threshold(gray,120,255,cv.THRESH_BINARY) return thresh'''利用列元素求和进行字符分割,效果会比较好,但是出了一些问题。'''# 分割图像,给定参数为要分割字符的开始位def find_end(start,black,width,black_max): end=start+1 for m in range(start+1,width-1): if (black[m])>(0.95*black_max): end=m break return end'''思路就是从左开始检测匹配字符,若宽度end-start小与5则认为为边界。直接略掉。'''def cut_str(thresh): black = [] # 记录每一列的黑色像素总和 height = thresh.shape[0] # 263 width = thresh.shape[1] # 400 black_max = 0 # 仅保存每列,取列中黑色最多的像素总数 # 计算每一列的黑白像素总和 for i in range(width): line_black = 0 # 这一列黑色总数 for j in range(height): if thresh[j][i] == 0: line_black += 1 black_max = max(black_max, line_black) black.append(line_black) n=1 start=1 end=2 #这边从1开始 while n < width - 2: n += 1 start=n end=find_end(start,black,width,black_max) n=end if end - start > 5: cj = thresh[1:height, start:end] #进行字符的裁剪 b_img=cv.resize(cj, None,fx=5,fy=3) contours, hierarchy=cv.findContours(b_img.copy(), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE) block=[] for c in contours: ''' 计算字符图像特征 ''' r = find_rectangle(c) a=(r[2]-r[0])*(r[3]-r[1]) s=(r[2]-r[0])/(r[3]-r[1]) block.append([c, r, a, s]) block=sorted(block, key=lambda block: block[2])[-1:] box=block[0][1] y_mia=box[0] x_min=box[1] y_max=box[2] x_max=box[3] cropImg = cv.resize(b_img[x_min:x_max, y_mia:y_max],(32,40)) ''' 这里得到的图片就是我们需要的字符图片。可以选择show或者保存下来。 ''' 四. 代码分析
这里主要要阐明几个方法。
cv.grabCut()
它主要实现的是一个交互式的前景提取。
大致过程如下:
额,这个很容易看明白就不需要讲解了。
如下为它的参数要求。
gray=cv.filter2D(gray,-1,np.ones((3,3),np.float32)/9)
这个filter2D之前的博客讲的很清楚,不过这里还是得再说。
cv2.filter2D():使用自定义内核对图像进行卷积,它不仅可以让图像变得模糊,还可以让图像变得更锐化。该方法的使用花样很多,这里不细说,-1参数代表所需要的的深度,这里是默认。kernel表示卷积核。可以记住这种方法,一般的模糊和锐化不会改动其他地方,最大的改动应该就是自己定义的卷积核,import cv2 as cvimport numpy as np#自定义模糊def get_customer_burry(image): #定义卷积核,算子 #该方法与均值模糊 5*5的卷积类似 #kernel=np.ones([5,5],np.uint32)/25 #kernel=np.array([[1,1,1],[1,1,1],[1,1,1]],np.float32)/9 #image=np.float32(image) #卷积的锐化算子 kernel=np.array([[0,-1,0],[-1,5,-1],[0,-1,0]],np.float32) dist=cv.filter2D(image,-1,kernel=kernel) cv.imshow('customer',dist) 这段代码小伙伴可以自己试试。它可以实现锐化或者模糊。
剩下的大多就是算法层面了,也不需要多讲了,自己多看看思考思考就行。
转载地址:http://lkcki.baihongyu.com/